In a long-running cluster, there might be an unequal distribution of data across Datanodes. This could be due to failures of nodes or the addition of nodes to the cluster. To make sure that the data is equally distributed across Datanodes, it is important to use Hadoop balancer to redistribute the blocks.
How rebalancing works
– HDFS rebalancer reviews data block placement on nodes and adjusts the blocks to ensure all nodes are within x% utilization of each other.
– Utilization is defined as an amount of data storage used.
– x is known as the threshold.
– A node is underutilized if its utilization is less than (average utilization – threshold).
– A node is overutilized if its utilization is more than (average utilization + threshold).
Adding Balancer Service in Cloudera Manager
Before you can rebalance a cluster, we need to add the balancer service. The following are the steps to add the Balancer service:
1. Navigate to the Clusters menu and select Add Role Instance from the “HDFS Actions” drop-down menu.
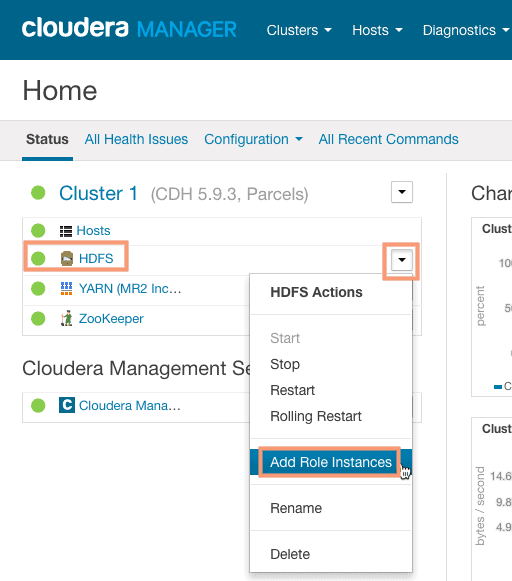
2. Click on Select a host for the Balancer section to bring up the host selection screen and select the desired host for the Balancer Role. I have selected master.localdomain for balancer role assignment.
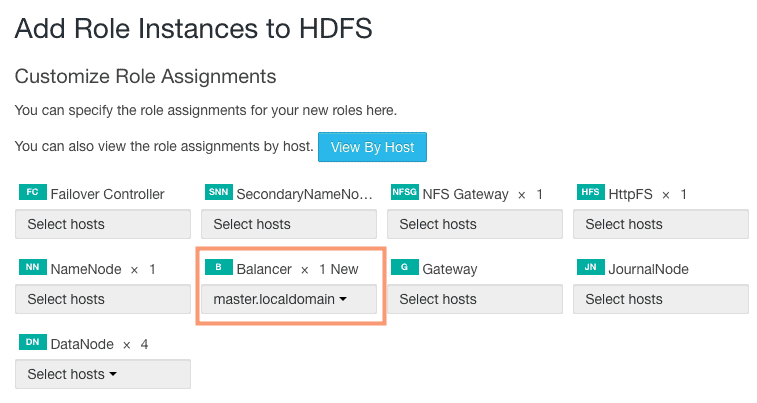
3. Click on Continue and you should now see the Balancer service added, as shown in the following screenshot:
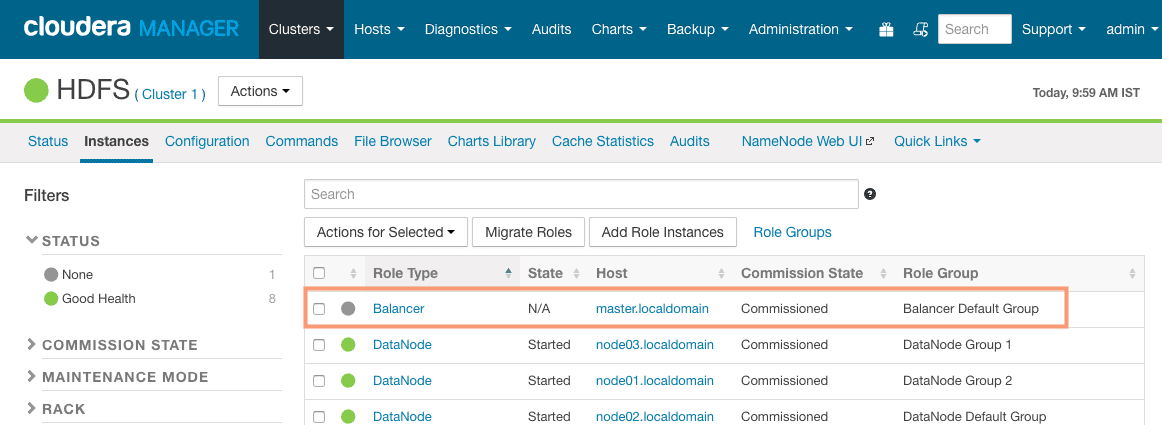
As shown in the screenshot, you should see the balancer state as “N/A“. This is because the Balancer role does not run continuously. It is triggered manually whenever there is a requirement in the cluster for balancing.
Balancer Configuration
When you run a Balancer job on the cluster it is run with a specific “Rebalancing Threshold“. The default value of Rebalance Threshold is 10 %.
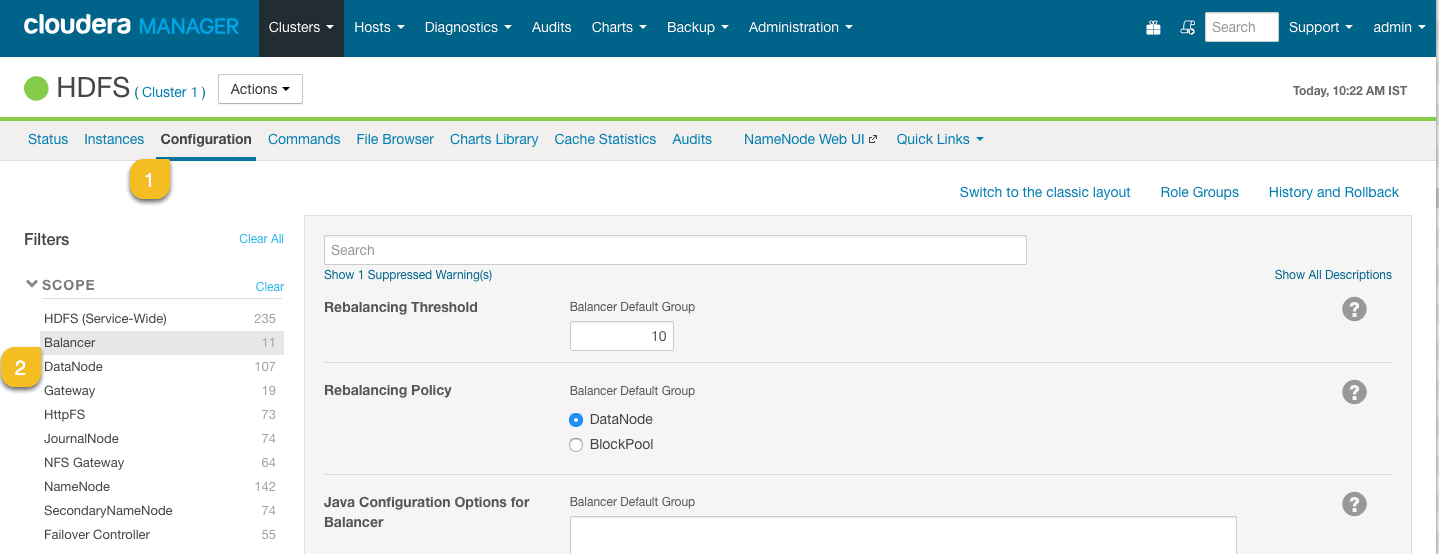
Rebalancing Threshold
The balancer threshold defines the percentage of cluster disk space utilized, compared to the nodes in the cluster. For example, let’s say we have 10 Datanodes in the cluster, with each having 100 GB of disk storage totaling about 1 TB.

So, when we say the threshold is 5%, it means that if any Datanode’s disk in the cluster is utilized for more than 50 GB (5% of total cluster capacity), the balancer will try to balance the node by moving the blocks to other nodes. It is not always possible to balance the cluster, especially when the cluster is running near maximum disk utilization.
Rebalancing Policy
The policy that should be used to rebalance HDFS storage. The default “DataNode” policy balances the storage at the DataNode level. The “BlockPool” policy balances the storage at the block pool level as well as at the DataNode level. The BlockPool policy is relevant only to a Federated HDFS service.

Rebalancing the cluster from Cloudera Manager
Once the Balancer service is installed successfully, you can perform the rebalancing operation. Follow the steps outlined below to perform the rebalancing operation from Cloudera Manager:
1. Navigate to the Clusters menu and select HDFS.

2. Navigate to the Instances tab and click on the Balancer service from the list of services to navigate to the balancer screen as shown in the following screenshot:
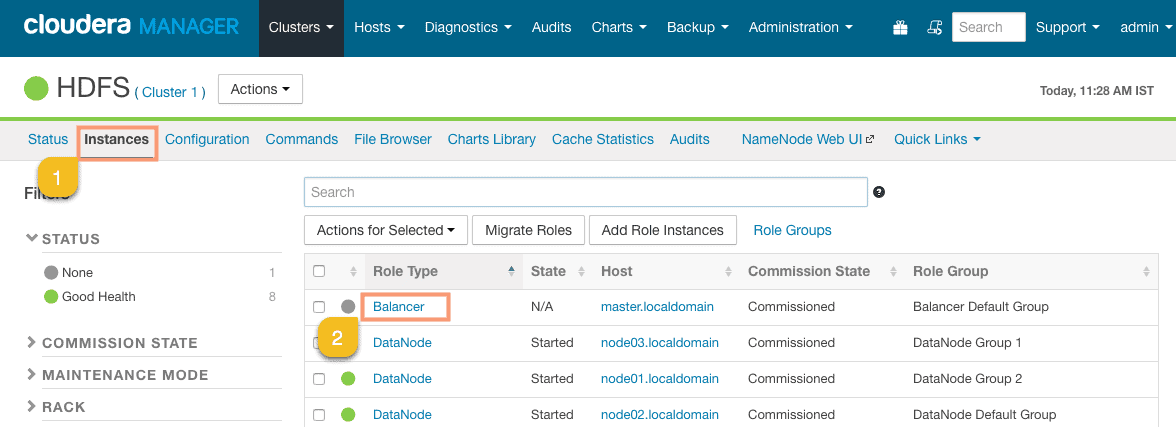
3. Click on the Actions button and click on Rebalance as shown in the following screenshot:
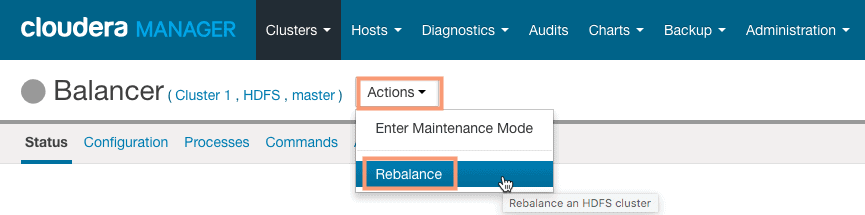
4. Click on Rebalance to start the rebalancing operation. On successful completion, the data blocks should be balanced across the datanodes on the cluster. In our case, we do not have much to rebalance.
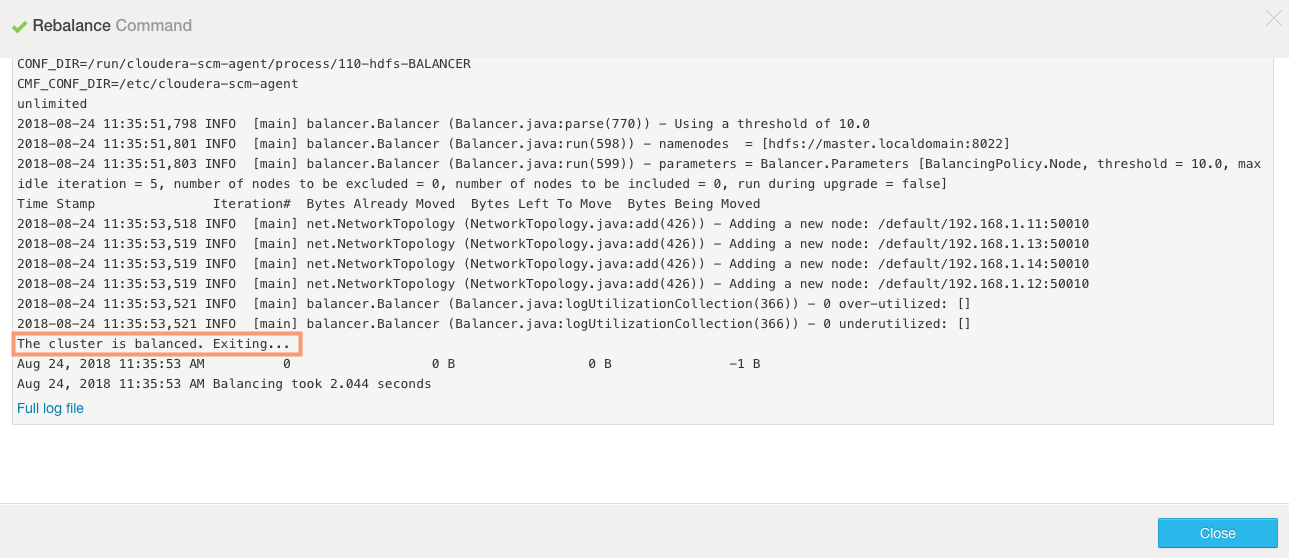
Rebalancing the cluster from Command Line
You can also perform the Rebalancing operation from the command line. Follow the steps outlined below to initiate rebalancing operation from the master node.
1. Login to the master.localdomain node and switch to the user “hdfs”.
[root@master ~]# su - hdfs
2. Execute the balancer command as shown in the following screenshot:
$ hdfs balancer
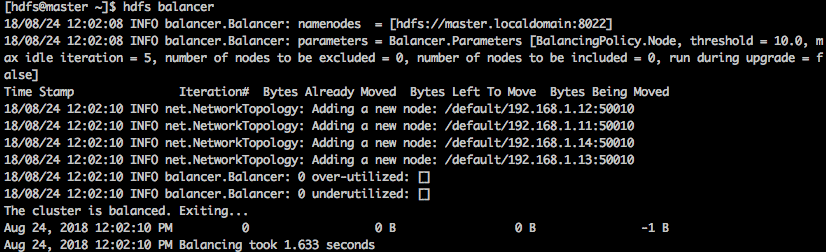
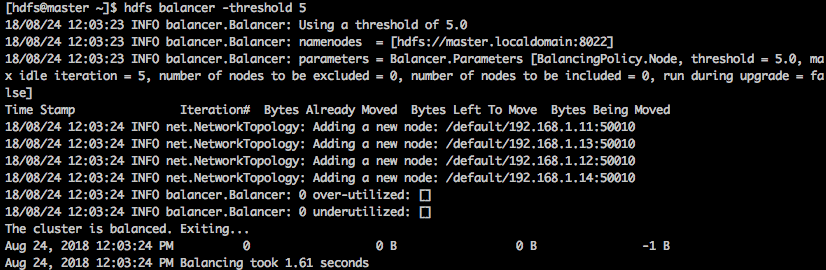
3. By default, the balancer threshold is set to 10%, but we can change it, as shown below:
$ hdfs balancer -threshold 5
HDFS balancer Bandwidth
You can also control the bandwidth usage during the rebalancing operation which is 10MB per second by default. The command shown below specifies a bandwidth in bytes/sec (not bits/sec) that each DataNode can use for rebalancing.
$ hdfs dfsadmin -setBalancerBandwidth [bandwidth in bytes per second]
For example: to set the bandwidth as 100MB per second, execute the below command as “hdfs” user.
$ hdfs dfsadmin -setBalancerBandwidth 100000000
Conclusion
An HDFS cluster can become “unbalanced” if:
– some nodes have much more data on them than the other nodes.
– Example: add a new node to the cluster.
– Even after adding some files to HDFS, this node will have far fewer data than others.
– During a job execution, this node will use much more network bandwidth as it retrieves a lot of data from other nodes.
Clusters can rebalanced using the “hdfs balancer” utility or from the Cloudera Manager Rebalancer utility.